Notes on Apache Jena StreamRDFWriter
Apache Jena project is like a box full of interesting things—at least if you love programming. One of its many features, is stream processing.
The graphs in Jena may contain very large datasets, with giga- or terabytes. Some queries may be very large, and then sending the whole result would be simply impracticable.
Instead, the data will go through ARQ. ARQ is a query engine for Jena that supports SPARQL. There is one piece of code there that I found interesting while reviewing a small pull request: org.apache.jena.riot.system.StreamRDFWriter.
It is responsible for writing graph data in a streaming fashion. (See stream processing for programming models and more.)
Stream factories
StreamRDFWriter holds several implementations (as static members) of StreamRDFWriterFactory. The factory has one responsibility only, to create streams (StreamRDF), for a certain format and context.
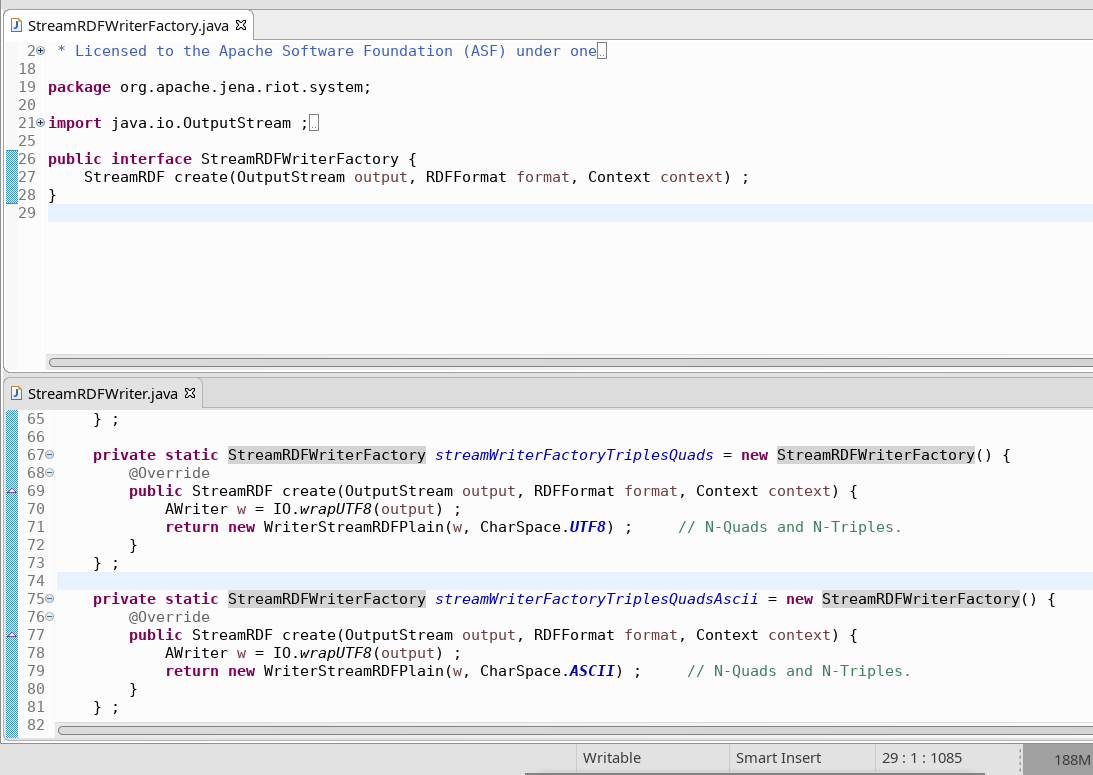
Streams writer registry
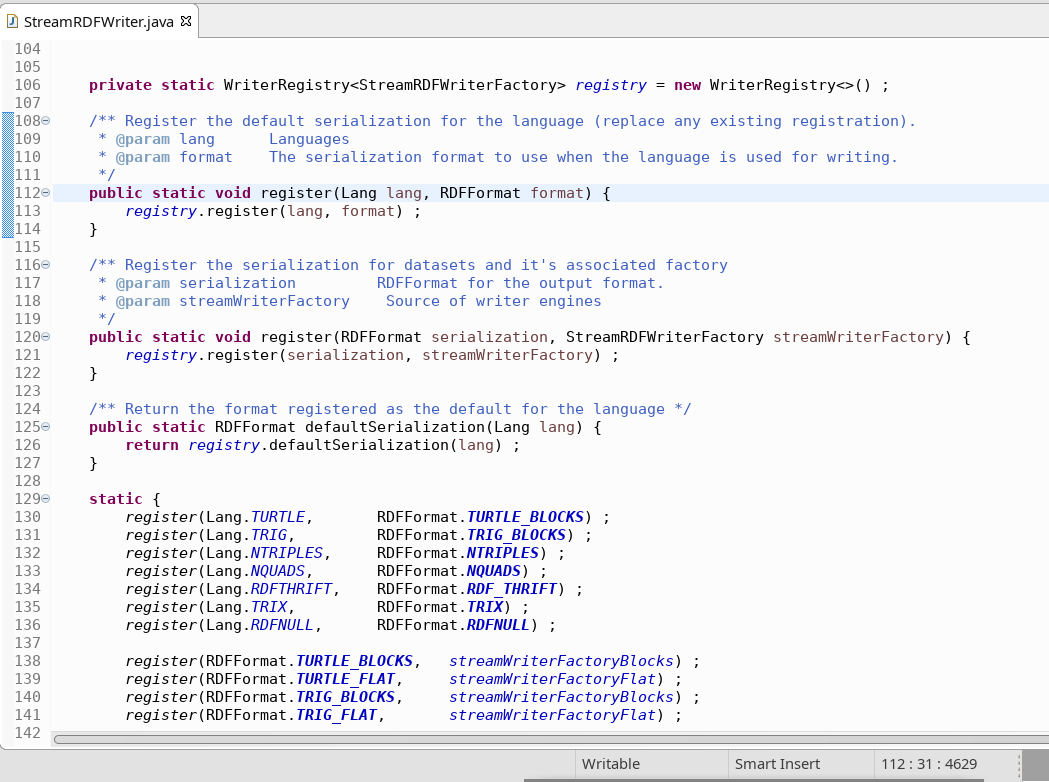
All these factories and streams, the writer also needs a registry. It is used to access the writers required for streams using certain languages.
So if you have your graph dataset, and need to retrieve triples as thrift, you will interrogate the registry asking for a factory of that language (Turtle, N-Triples, RDF-Thrift, etc) or format (Flat Turtle, N-Quads, N-Triples-ASCII, RDF-Thrift, etc).
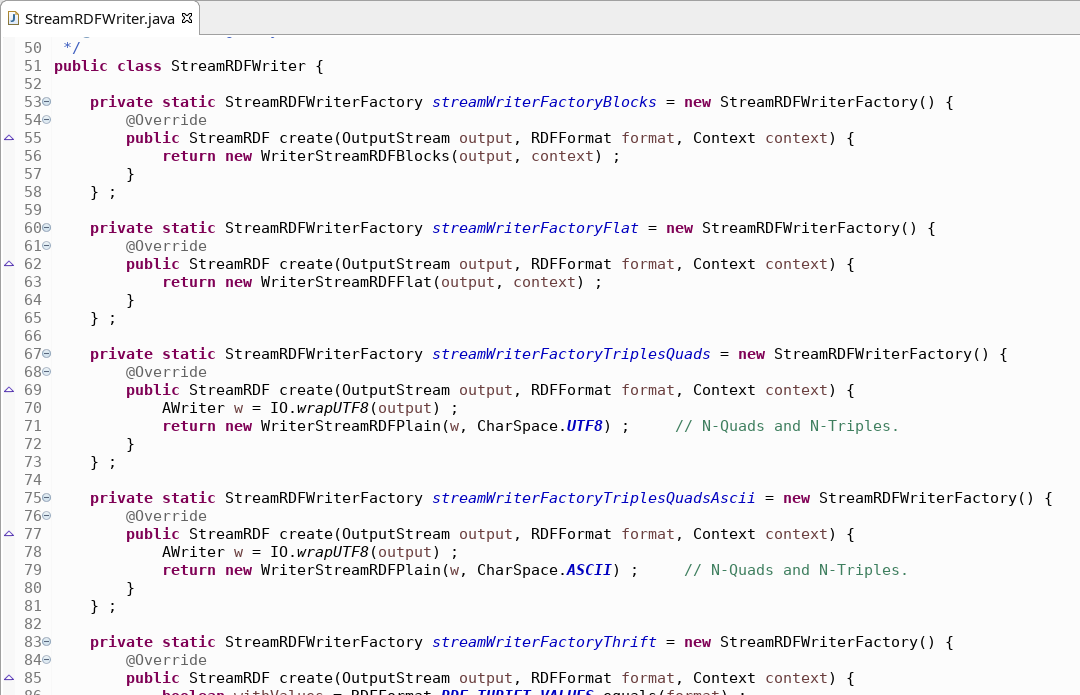
Writing data to streams
Each writer has one responsibility too—I really like the design of certain modules in Jena.
The action, however, happens somewhere else. In the StreamRDFOps and in the Iterator implementations is where the stream processing really takes place.
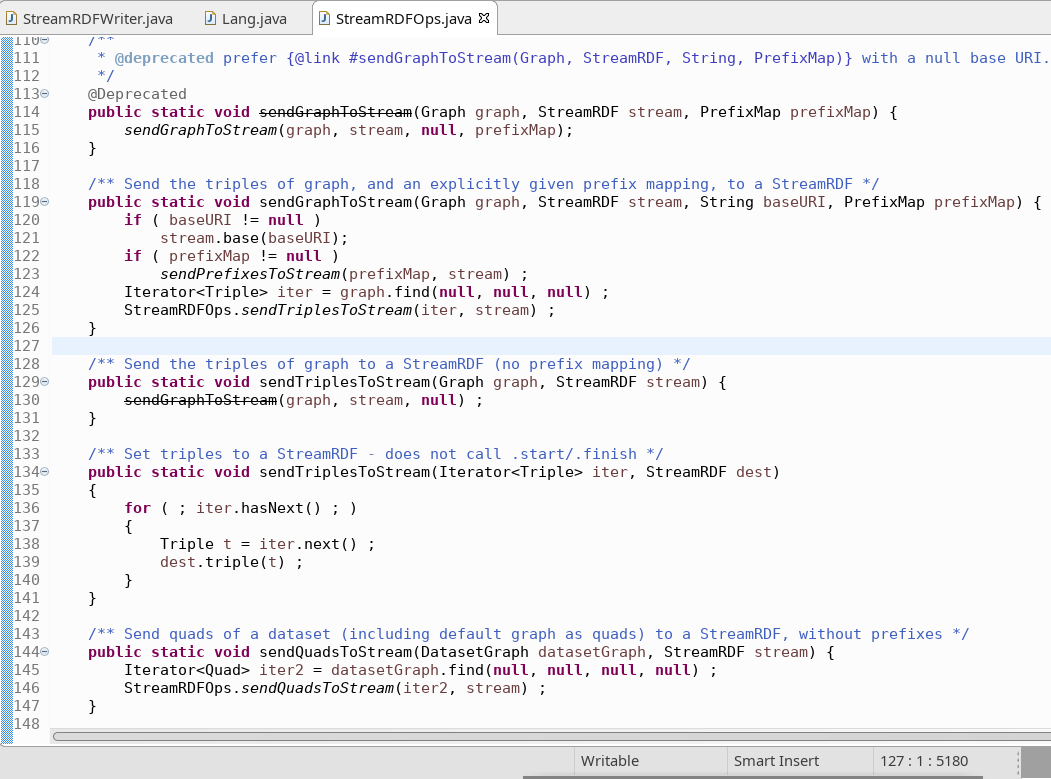
But this goes beyond the StreamRDFWriter. So that’s all for today.
Categories: Blog
Tags: Apache Software Foundation, Apache Jena, Stream Processing, Open Source, Java