What happens when you upload a Turtle file in Apache Jena Fuseki
I am working on an issue for Skosmos that involves preparing some Turtle files and uploading them using Apache Jena Fuseki’s web interface.
The issue is now pending feedback, which gives me a moment to have fun with something else. So I decided to dig down the rabbit hole and start learning more about certain parts of the Apache Jena code base.
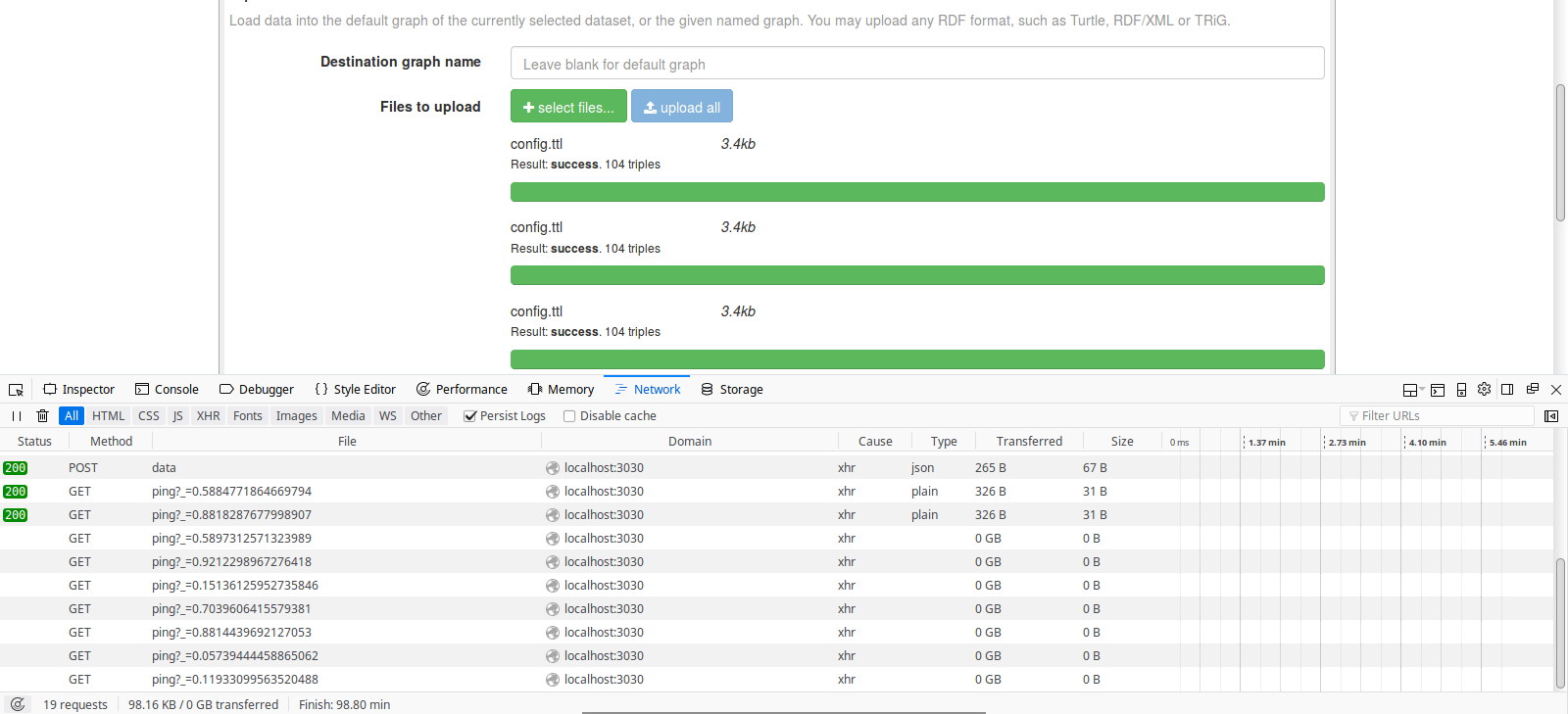
This post will be useful to myself in the future, as a note-taking in a series, so that I remember how things work - you never know right? But hopefully this will be useful to other wanting to understand more about the code of Apache Jena.
Where upload happens - SPARQL_Upload and Upload (Fuseki Core)
Knowing a bit of the code base, I went straight to the SPARQL_Upload class,
from the Fuseki Core module. Set up a couple of breakpoints, uploaded my file,
but nothing. Then tried on its package-neighbour class, Upload.
Actually, it is easier to understand seeing the class hierarchy, and knowing that when I run the application in Eclipse, it is running with Jetty, serving servlets (there is no framework like Wicket, Struts, etc, involved).
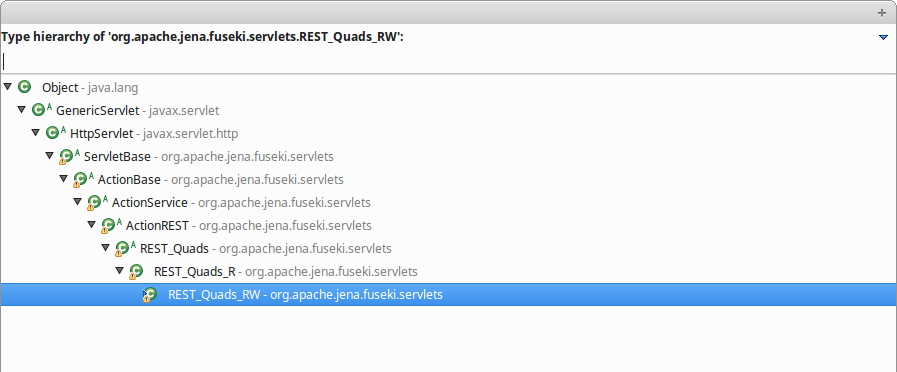
Several filters are applied to the HTTP request too, like Cross Origin, Shiro, and
the FusekiFilter. The latter looks at the requests to see if it includes a dataset.
If a dataset is found - it is in our case - then it hands the request over to
the right class to handle it.
REST_Quads_RW will take care of the upload action, using the Upload class where my
breakpoint stopped.
Upload#incomingData() (Fuseki Core)
Upload#incomingData() starts by checking the Content Type from the request. In my case
it is a multipart/form-data. Then it calls its other method #fileUploadWorker().
#fileUploadWorker() creates a ServletFilterUpload, from Apache Commons FileUpload.
With that, it opens a stream for the file, retrieves its name and other information,
such as the content type.
Ah, the content type is interesting too. It defaults to RDFXML, but what’s interesting
is the comment.
if ( lang == null )
// Desperate.
lang = RDFLanguages.RDFXML ;
Well, in this case we are getting a Lang:Turtle. So it now knows that it has a Turtle
file, but it still needs to parse it.
ActionLib#parse() (Fuseki Core)
Upload calls ActionLib#parse(), which uses RDFParserBuilder to build a parser.
It applies a nice fluent API design when doing that.
RDFParser.create()
.errorHandler(errorHandler)
.source(input)
.lang(lang)
.base(base)
.parse(dest);
Side note to self: the `RDFParser` has a `canUse` flag. It seems to indicate the parser can be used just once. Though it looks actually it works until the stream is closed...
So RDFParserBuilder will call RDFParser, which in turn will use the
classes LangTurtle and LangTurtleBase.
LangTurtle (ARQ)
ARQ is a low level module in Jena, responsible for parsing queries, and also some of the interaction with graphs and datasets.
LangTurtle extends LangTurtleBase. Their task starts by populating
the prefixMap, which contains all those prefixes used in queries like
rdfs, void, skos, etc.
Then it will keep parsing triples until it finds an EOF. For every
triple, after the Predicate-Object-List is found, it calls
LangTurtle#emit().
The #emit()method creates a Triple object (Jena Core, graph package).
And also a StreamRDFCountingBase to keep track of statistics to display
back to the user.
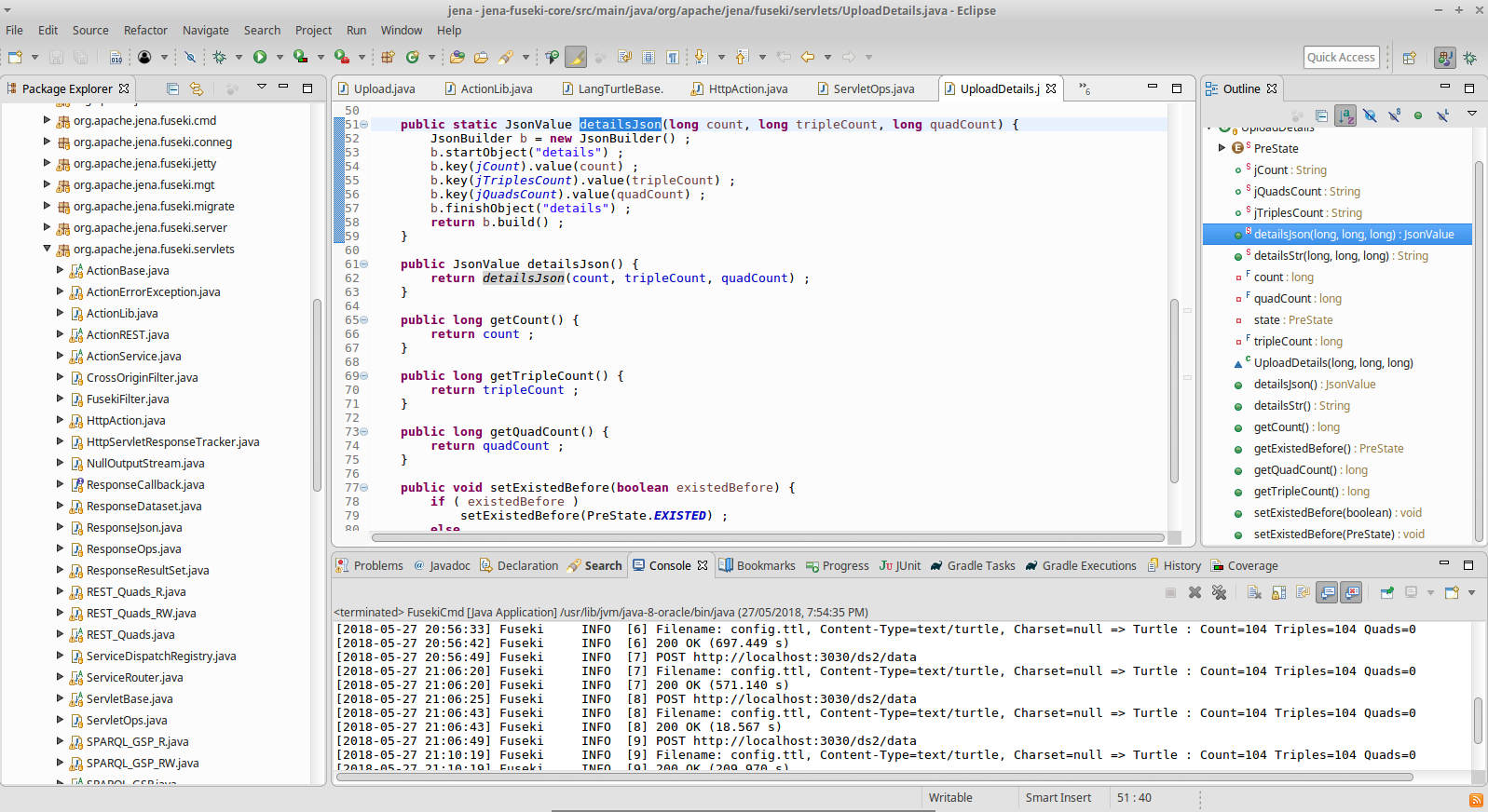
StreamRDFCountingBase extends StreamRDFWrapper, and wraps - as per name -
other StreamRDF’s, such as ParserOutputDataset.
ParserOutputDataset holds a reference to the DatasetGraph and also to the
prefixMap populated earlier in LangTurtle. For each Triple that we have
it will call the DatasetGraph#add method, creating a new Quad with the
default graph name.
Conclusion
Finally, readers and streams are closed. An UploadDetails object is created
holding stats collected in StreamRDFCountingBase, which are also used for
logging.
Upload#incomingPath() will return the UploadDetails. If there are no errors
then the transaction will be committed. It involves again classes from ARQ and
TDB (for journaling), but that will be for another post.
The final method called in the Upload class will be detailsJson(), which
returns the object as JSON. This JSON string is then finally returned to the
user.
So that’s it. Probably the next step will be to learn how DatasetGraph works,
or maybe more about transactions in Jena.
Happy hacking !
Categories: Blog
Tags: Apache Software Foundation, Jena, Opensource, Programming