Contributing to Apache Jena
As I mentioned in my [previous post]({% post_url 2014-10-11-basic-workflow-of-a-sparql-query-in-fuseki %}), I am using Apache Jena for a project of a customer. I had never used any triple store, nor a SPARQL Endpoint server before. But for being involved with the Apache Software Foundation, and since the company itself is using several Apache components, it was only natural Jena to be our first choice.
It has served us very well so far. At the moment we have less than 100 queries per day, but the project is still under development and we expect 1000 queries per day by the first quarter of 2015 and 1000000 near the end of 2015. We also have few entries in TDB, but expect to grow this number to a few million before 2016.
When I work for companies and we use Open Source Software (OSS) in a project, I always prepare assessment reports to include in the deliveries. In this report I justify the choice of Open Source Software (as well as commercial software). Sometimes I am lucky to work for a company that asks me to include hours to work on OSS :-)
I use Trello to triage issues in OSS projects (and for several other things). I have a board with several cards for Open Source. About a month ago I set up one for Jena and listed the issues that I thought I could contribute to.
I annotate easy issues with a “lhf” suffix for Low Hanging Fruit issues, and delete issues from the card once I submit a patch or update it (and include it in another card for the TupiLabs reports).
Most of the issues I included in the card for Jena had been created over two years ago, and hadn’t been updated in a while. When you test these issues against the current code, usually you find that some of them have already been fixed. Other issues included documentation problems, and minor features. I didn’t find any blocker issue that would impede us to use Jena in production.
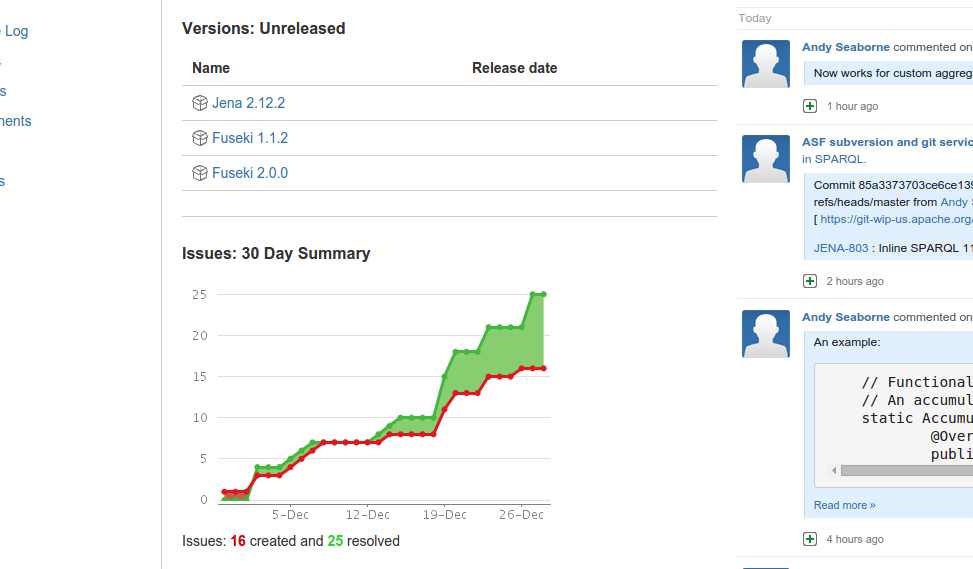
The picture above shows the past 30 days activity summary in JIRA for Jena. The red line shows issues created, and the green line issues resolved. Andy Seaborne was very active in the past days and fixed several issues that were too old and had already been fixed in the trunk, and kindly merged patches and pull requests.
Some issues like JENA-632 will take a longer time to fix, but I’m getting used to Jena’s source code, and at the same getting more confident to use it in production - especially with a supportive OSS community. We are using Jena for RDF with Hadoop, and I learned that I can replace some custom Writables by others in the Jena Hadoop submodule.
By the way, even though this project ends in April, I intend to continue contributing to Jena. There is a lot of parts of the code that I would love to be able to understand and contribute, in special the Graph database, optimization techniques for SPARQL queries, the grammars used in the project, Fuseki v2 and enhance its testing harness (as well as the test coverage).
If you are looking for a interesting project to get you started with semantics, linked data, RDF, and even graphs and database querying, try contributing to Jena. I bet you’ll have a lot of fun!
Happy hacking and happy 2015!
Categories: Blog
Tags: Jena, Apache Software Foundation